Pipelines de Scraping Programados
Scrapers automatizados basados en Playwright que se ejecutan según horario, manejan anti-bot, y entregan datos limpios — siempre.
Capacidades
Qué Extraigo
Si lo puedes ver en un navegador, lo puedo extraer. Estas son las plataformas y tipos de datos con los que trabajo regularmente.
E-Commerce y Retail
Datos de productos, precios, reseñas e inventario de grandes retailers y tiendas Shopify.
- Título, marca, precio, descuento %, SKU
- Calificaciones, cantidad de reseñas, imágenes
- Paginación, variantes, carga dinámica
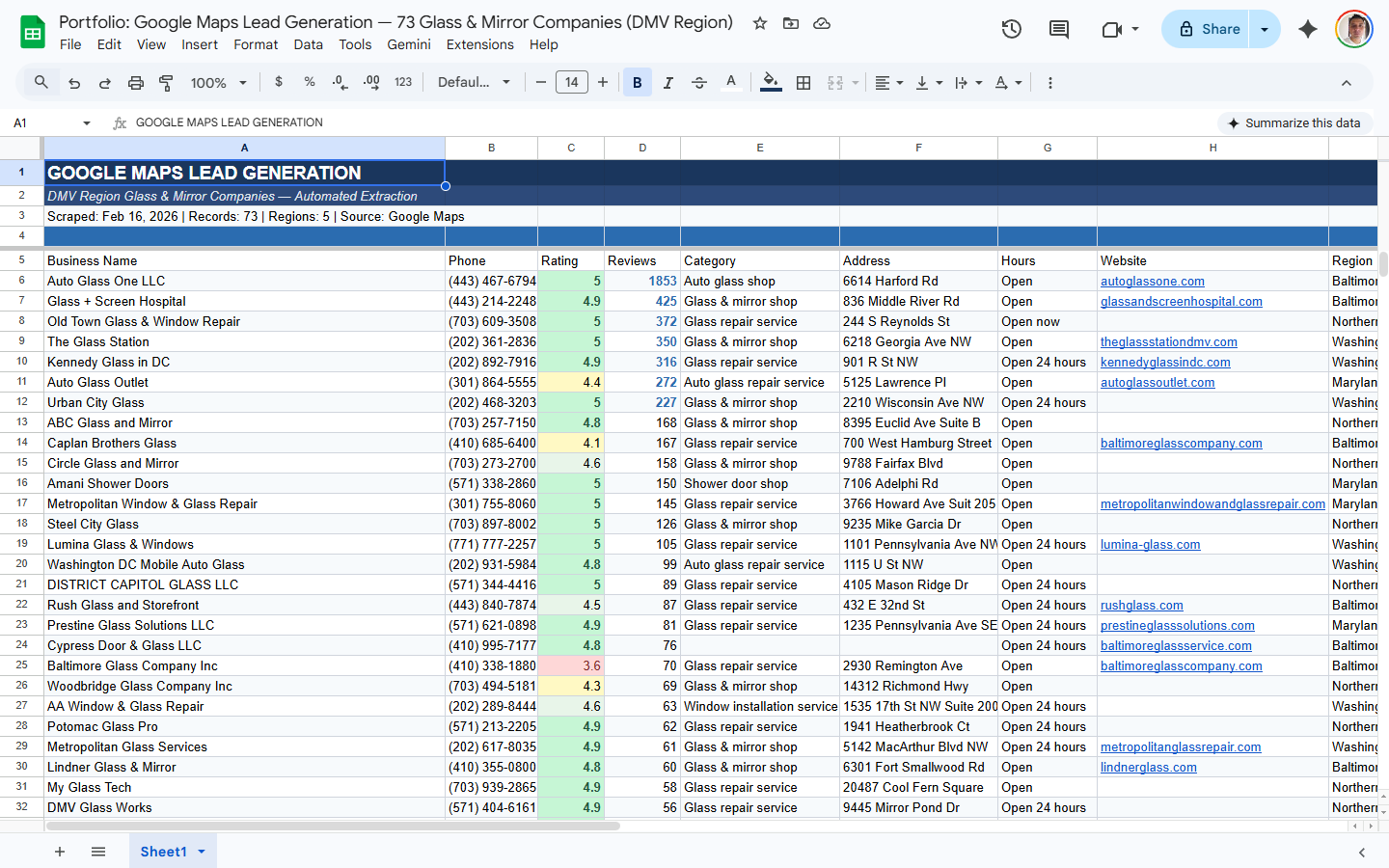
Generación de Leads
Datos de contacto empresarial de mapas, directorios y listados de industria — listos para prospección.
- Nombre, dirección, teléfono, web, email
- Calificación Google, reseñas, horarios
- Sin duplicados, listo para importar al CRM
Bolsas de Trabajo
Listados de empleo con datos salariales, habilidades e info de empresa de las principales bolsas.
- Título, empresa, ubicación, rango salarial
- Habilidades/tags, fecha, URL de aplicación
- Scraping por API + navegador
Bienes Raíces
Listados de propiedades, precios y datos de mercado de las principales plataformas inmobiliarias.
- Dirección, precio, habitaciones, m²
- Agente, días en mercado, fotos
- Historial de precios y tendencias
Sitios Protegidos
Sitios con sistemas anti-bot agresivos que bloquean scrapers básicos. Uso navegadores sigilosos y scraping en la nube.
- Playwright sigiloso + rotación de huella digital
- Scraping en la nube para los más difíciles
- Retrasos aleatorios y rate limiting respetuoso
Cualquier Otro Sitio
Noticias, viajes, redes sociales, bases de datos públicas, sitios de reseñas — si lo puedes ver, lo puedo extraer.
- APIs, feeds JSON y parsing de HTML
- Sitios con login (con tus credenciales)
- Scroll infinito y contenido JS dinámico
Trayectoria
Resultados Reales
1,000+
Productos Monitoreados Diario
Precios de competidores extraídos cada día de Amazon, tiendas retail y competidores directos
4
Sitios de Competidores
Scrapers en producción ejecutándose contra sitios e-commerce protegidos con bypass anti-bot
9
Canales de Venta Agregados
Amazon, Walmart, sitio web, mayoreo y más — unificados en un solo dashboard en vivo
6+ meses
Funcionando en Producción
Pipelines automatizados ejecutándose diario sin intervención — cero mantenimiento manual
Estos no son demos — son sistemas en producción que impulsan decisiones de negocio reales cada día.
Entregables
Lo que Obtienes
Scrapers Playwright personalizados
Construidos específicamente para tus sitios web objetivo, manejando contenido dinámico y renderizado JavaScript.
Anti-bot y modo sigiloso
Plugins de sigilo, retrasos aleatorios y rotación de huellas digitales para evitar detección.
Ejecuciones programadas (diarias/por hora)
Programación basada en cron para que tus datos estén siempre frescos, sin activación manual.
Limpieza y normalización de datos
Los datos crudos se limpian, deduplicn y formatean antes de la entrega.
Entrega a Google Sheets / CSV
Datos enviados directamente a tu Google Sheet o guardados como CSV para descarga.
Alertas de error y lógica de reintento
Reintentos automáticos en caso de fallo con notificaciones por email para mantenerte siempre informado.
Alcance y Precio
Cada Proyecto Es Diferente
Evalúo cada proyecto individualmente según tus datos, objetivos y plazos. Sin paquetes genéricos — solo una solución diseñada para lo que realmente necesitas.
Volumen de Datos
La cantidad de SKUs, páginas o puntos de datos a procesar define el alcance del proyecto.
Formato de Entrega
CSV, dashboard en vivo, integración API o reportes automatizados — cada uno tiene diferente complejidad.
Soporte Continuo
Entrega única versus monitoreo continuo, mantenimiento e iteración sobre resultados.
Proceso
Cómo Funciona
Alcance
Definir qué datos necesitas, de qué fuentes y con qué frecuencia. Mapear la estructura del sitio objetivo y sus defensas anti-bot.
Construir
Desarrollar el scraper con Playwright (navegador headless), manejo de errores, lógica de reintentos y guardado de checkpoints.
Limpiar
Parsear, normalizar y validar los datos extraídos. Eliminar duplicados, corregir codificación y estructurar en tu formato objetivo (JSON, CSV, Google Sheet).
Programar
Configurar ejecuciones automatizadas — diarias, semanales o intervalos personalizados. Alertas de monitoreo si el scraper falla o la calidad de datos baja.
Entregar
Datos enviados a tu destino preferido: Google Sheets, base de datos, endpoint API, bucket S3 o directo a un dashboard.
Análisis Profundo
Conocimiento Experto
Navegadores Headless vs. con Interfaz
Los navegadores headless (sin ventana visible) son más rápidos y usan menos memoria — ideales para scraping simple. Pero muchos sistemas anti-bot detectan el modo headless mediante fingerprinting del navegador: información de GPU ausente, contexto de audio faltante o navigator.webdriver en true.
Para sitios protegidos, uso modo con interfaz y plugins de sigilo que parchean estos vectores de fingerprinting. El scraper ejecuta una ventana de navegador real (puede estar oculta fuera de pantalla) que luce idéntica a un visitante humano. Es más lento pero dramáticamente más confiable contra detección de bots sofisticada.
Estrategia de Programación: No Hagas Scraping Cuando Todos lo Hacen
La mayoría de los scrapers automatizados se ejecutan a medianoche o en punto de la hora. Los sitios objetivo ven picos de tráfico en esos momentos y es más probable que apliquen rate-limiting o activen CAPTCHAs. Programa tus scrapes en horarios impares — 3:47 AM, 11:23 AM — y agrega jitter aleatorio (±5 minutos) a cada ejecución. Distribuir solicitudes en horas de baja demanda reduce el riesgo de detección y mejora las tasas de éxito.
¿Listo para pipelines de datos que posees?
Deja de depender de herramientas SaaS de scraping. Construyamos pipelines que tú controlas.
Contáctame