Scheduled Scraping Pipelines
Automated Playwright-based scrapers that run on schedule, handle anti-bot, and deliver clean data — every time.
Capabilities
What I Scrape
If you can see it in a browser, I can extract it. Here are the platforms and data types I work with regularly.
E-Commerce & Retail
Product data, pricing, reviews, and inventory from major retailers and Shopify stores.
- Title, brand, price, discount %, SKU
- Ratings, review counts, images
- Pagination, variants, dynamic loading
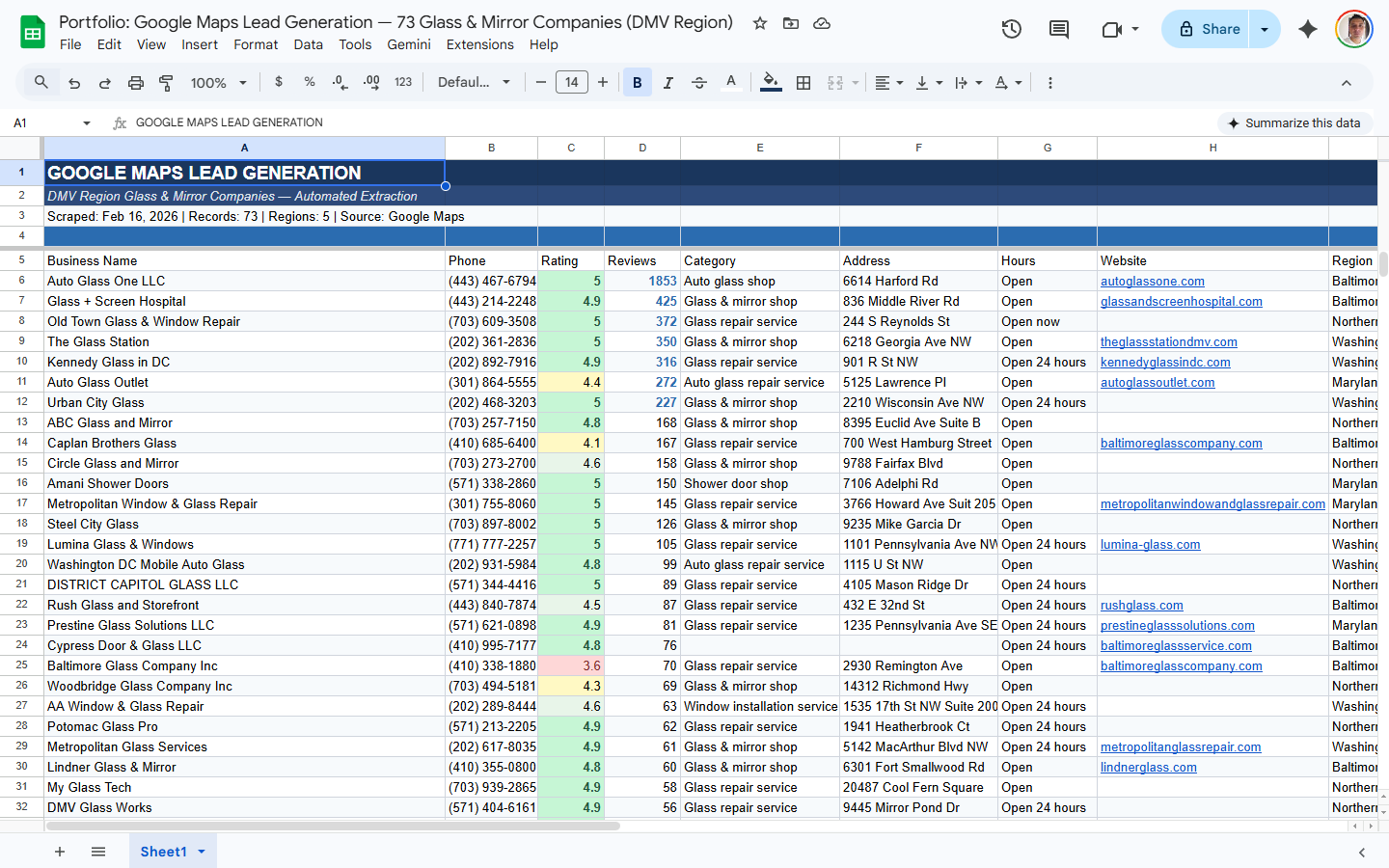
Lead Generation
Business contact data from maps, directories, and industry listings — ready for outreach.
- Name, address, phone, website, email
- Google rating, review count, hours
- Duplicates removed, ready for CRM import
Job Boards
Job listings with salary data, skills, and company info from major boards and niche sites.
- Title, company, location, salary range
- Skills/tags, posting date, apply URL
- API + browser scraping approaches
Real Estate
Property listings, prices, and market data from major real estate platforms.
- Address, price, beds/baths, sqft
- Listing agent, days on market, photos
- Price history and market trends
Protected Sites
Sites with aggressive anti-bot systems that block basic scrapers. I use stealth browsers and cloud scraping to get through.
- Stealth-mode Playwright + fingerprint rotation
- Cloud scraping for the hardest targets
- Randomized delays and respectful rate limiting
Anything Else
News, travel, social media, government databases, review sites — if you can see it, I can scrape it.
- APIs, JSON feeds, and HTML parsing
- Login-required sites (with your credentials)
- Infinite scroll and dynamic JS content
Track Record
Real Results
1,000+
Products Monitored Daily
Competitor pricing scraped every day across Amazon, retail sites, and direct competitors
4
Competitor Sites Scraped
Production scrapers running against protected e-commerce sites with anti-bot bypasses
9
Sales Channels Aggregated
Amazon, Walmart, website, wholesale, and more — unified into one live dashboard
6+ mo
Running in Production
Automated pipelines running daily without intervention — no babysitting required
These aren't demos — they're production systems powering real business decisions every day.
Deliverables
What You Get
-
Custom Playwright scrapers
Purpose-built for your target websites, handling dynamic content and JavaScript rendering.
-
Anti-bot & stealth mode
Stealth plugins, randomized delays, and fingerprint rotation to avoid detection.
-
Scheduled runs (daily/hourly)
Cron-based scheduling so your data is always fresh, no manual triggers needed.
-
Data cleaning & normalization
Raw scraped data is cleaned, deduplicated, and formatted before delivery.
-
Google Sheets / CSV delivery
Data pushed directly to your Google Sheet or saved as CSV for download.
-
Error alerts & retry logic
Automatic retries on failure with email notifications so you're always informed.
Scope & Pricing
Every Project Is Different
I scope every engagement individually based on your data, goals, and timeline. No cookie-cutter packages — just a solution built around what you actually need.
Data Volume
Number of SKUs, pages, or data points to process drives the scope of the project.
Delivery Format
Raw CSV, live dashboard, API integration, or automated reporting — each has different complexity.
Ongoing Support
One-time delivery versus ongoing monitoring, maintenance, and iteration on results.
Process
How It Works
Scope
Define what data you need, from which sources, and at what frequency.
Build
Develop the scraper with Playwright, error handling, retry logic, and checkpoint saving.
Clean
Parse, normalize, and validate extracted data. Remove duplicates and structure into your format.
Schedule
Set up automated runs — daily, weekly, or custom intervals with monitoring alerts.
Deliver
Data pushed to Google Sheets, database, API endpoint, S3 bucket, or dashboard.
Deep Dive
Expert Insight
Headless vs. Headed Browsers
Headless browsers (no visible window) are faster and use less memory — great for simple scraping. But many anti-bot systems detect headless mode through browser fingerprinting: missing GPU info, absent audio context, or navigator.webdriver being true.
For protected sites, I use headed mode with stealth plugins that patch these fingerprinting vectors. The scraper runs a real browser window that looks identical to a human visitor. It's slower but dramatically more reliable against sophisticated bot detection.
Scheduling Strategy: Don't Scrape When Everyone Else Does
Most automated scrapers run at midnight or on the hour. Target sites see traffic spikes at these times and are more likely to rate-limit or trigger CAPTCHAs. Schedule your scrapes at odd times — 3:47 AM, 11:23 AM — and add random jitter (±5 minutes) to each run. Spreading requests across off-peak hours reduces detection risk and improves success rates.